
티스토리 뷰
바로 전 포스팅에서 데이터를 불러오고, 간단하게 데이터를 어떻게 보는지 알아봤어요.
오늘은 다양한 방법으로 데이터를 살펴볼거예요.
먼저 시각적으로 살펴볼까요?
저번 포스팅에서 저는 RLSPSS라는 데이터 프레임을 만들었어요.
쉽게 말하면 RLSPSS라는 이름 아래 제 데이터를 넣었어요.
이를 이용해서 간단하게 각 나이별로 분포가 어떻게 되는지 대략적으로 봐볼게요.
다양한 그래프로 데이터 살펴보기
먼저 그냥 수치를 봐도 돼요.
table(RLSPSS$Age)
제 데이터에서 나이 변수 이름이 Age예요.
저렇게 RLSPSS 데이터 프레임 안에서 Age의 테이블을 보겠다 라고 치면

이렇게 나오죠.
그럼 이걸 그래프로 보고싶다면?
barplot(table(RLSPSS$Age))
이렇게 하면

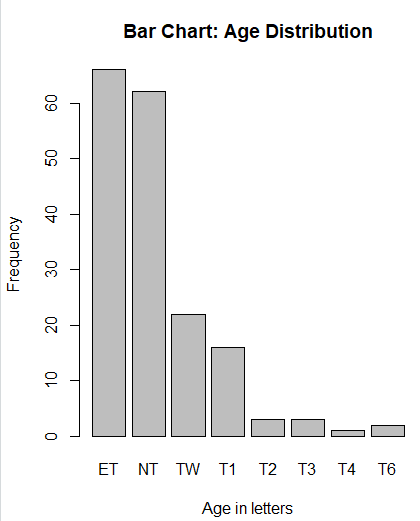
이런 그래프가 나오쥬. 위에 Zoom 누르면 커지고요.
만약 각각에 이름을 넣고싶다면,
barplot(table(RLSPSS$Age), names.arg = c("ET","NT","TW","T1","T2","T3","T4","T6"))
이런식으로 하면 돼요.
만약 데이터 포인트가 6갠데 이름을 5개만 지정하면 안돌아가요.
결과는 이렇게 나와요.

별로 어려운거 없죠? 좀 더 나가볼까요?
먼저 그래프 타이틀을 넣어볼게요.
main="Bar Chart: Age Distribution",
X축 이름도 넣을 수 있어요.
xlab="Age in letters",
lab은 label 줄임말 이예요.
Y축 이름도 넣을게요.
ylab="Frequency",
전부 합치면 다음과 같아요.

한 가지 좀 어려운게 있어요.
APA 스타일로 그래프를 넣으려면
Frequency (n)
이런식으로 들어가야 옳아요. n이 이탤릭체로 들어가야 하는거죠.
이건 어떻게 할까요?
expression 기능을 이용할 수 있어요.
expression(paste("Frequency(",italic("n"),")"))
paste는 일반적인 문자와 이탈릭체 등 여러 종류를 같이 쓸 수 있게 해줘요.
그리고 italic 전, 후로 콤마 보이시나요?
앞에 콤마는 "이제부터 이탤릭체"
뒤에 콤마는 "이제 이탤릭체 끝" 을 나타내요.
italic("") 이 따옴표 안에 오는게 이탤릭체가 되고요,
이걸 ylab에 넣으면 돼요.


이 외에도 색깔을 바꾸는 등 다양한 기능이 있어요.
하지만 나중에는 이 기능은 안쓰고 ggplot이란걸 쓰게 될거예요.
이건 그냥 연습용.
히스토그램(histogram)은 hist 명령어를 사용하시면 되고요.
히스토그램은 y축이 빈도니까 따로 ylab은 안해도 되겠죠?
아래 예시로 하나 만들어봤어요.
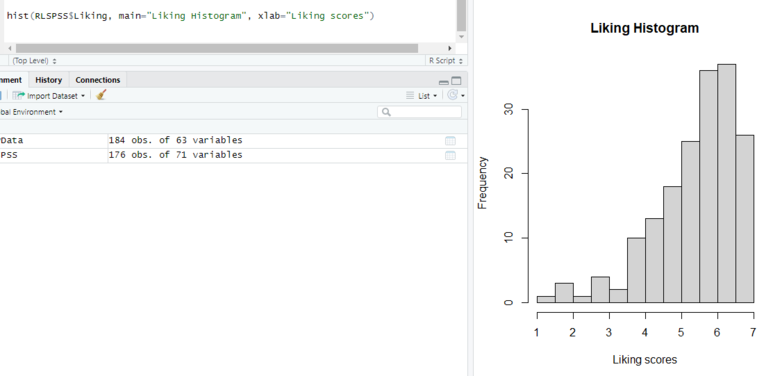
안녕 정규분포...
boxplot은 좀 달라요.
만약 나이에 따른 Liking 점수의 boxplot을 보고싶다면
boxplot(Liking~Age, data=RLSPSS, main="Liking by age", xlab="Age",ylab="Liking")
Liking~Age가 Age에 따른 Liking, 즉 x는 age y는 Liking이라는 뜻이예요.


이번에는 scatter plot을 해볼까요 이걸 산포도라 그러던가요?
regret과 liking간의 관계를 봐볼까요? (이론적으로 따지지 않고 그냥 예시로 볼게요.)
regret 변수 이름은 RES예요.
plot(x=RLSPSS$RES, y=RLSPSS$Liking, xlab="Regret", ylab="Liking")
결과가 이렇게 나왔어요.

흠.. 둘 간의 관계가 어떻게 되는걸까요? 얼핏 봐서는 잘 모르겠죠?
회귀 직선을 포함해볼게요.
abline 이 그래프에 선을 추가하는 명령어예요.
abline(lm(RLSPSS$Liking~RLSPSS$RES))
lm은 linear model이고요
~ 이 물결은 is regressed on 혹은 by 라고 생각하면 돼요.
앞에가 y/종속변수고 뒤가 x/독립변수예요.
만약 색을 추가하고 싶으면 col="색"


딱 눈으로 봐도 별 관계가 없어보이는군요.
수치로 데이터 살펴보기
이번엔 그래프가 아니라 그냥 수치로 간단하게 살펴볼게요.
만약 Liking 변수의 평균 등을 보고싶으면
summary(RLSPSS$Liking)
전 이게 가장 간단하더라고요.

이렇게 최소값부터 중위값 최대값 등 까지 보여줘요.
결측치가 있으면 결측이 몇개인지도 알려주고요.
만약 변수가 categorical이라면 각 그룹이 몇개씩 있는지 알려줘요.
전체의 summary를 알고싶으면
summary(RLSPSS)
만약 제일 첫 세로줄이 ID라서 필요없으니 그것만 빼고싶다면
sumary(RLSPSS[,-1])
응용 가능하겠죠?
summary에 나오지 않지만 많이 쓰는게 아마 분산과 표준편차겠죠?
분산은
var(RLSPSS$Liking)
만약 소수점 셋째 자리에서 반올림(둘째 자리까지 표기)하고 싶다면
round(var(RLSPSS$Liking), 2)


마찬가지로 표준편차는 sd 명령어를 쓰면 되고요
sd(RLSPSS$Liking)
심심하시면 sqrt (루트)를 이용해서 맞았나 확인해보셔도 되고요.
sqrt(var(RLSPSS$Liking))

오늘도 어려운건 없었죠? 아직도 R과 친숙해지는 단계예요.
다음 포스팅에서는 descriptive statistics 요약 테이블 만들고 데이터 converting하는걸 해볼게요.
오늘도 도움이 됐길 바라며, 열논문하세요!
도움이 됐다면 커피 한 잔 사주시면 감사하겠습니다^^
EPIK is 어려운 지식을 가능한 한 쉽게 공유하는 곳이예요 :)
Hey 👋 I just created a page here. You can now buy me a coffee!
www.buymeacoffee.com
'통계 이야기 > R을 공부해보자' 카테고리의 다른 글
| R 데이터를 살펴보자 2 (0) | 2020.06.14 |
|---|---|
| R 데이터 불러오기 (0) | 2020.06.07 |
| R 기초 2 (갖고 놀기) (0) | 2020.06.05 |
| R 기초 1 (갖고 놀기) (0) | 2020.06.03 |
| R 입문! (설치 및 세팅) (0) | 2020.06.03 |
- Mplus
- rstudio
- 매개효과
- SEM
- probing
- 구조방정식
- exploratory factor analysis
- 소속감
- social exclusion
- 사회심리
- indirect effect
- 프로세스
- MLM
- close relationships
- 탐색적 요인분석
- Hayes
- process
- structural equation modeling
- 조절분석
- 간접효과
- moderation
- amos
- 논문통계
- R 기초
- multilevel
- 부정적 평가 두려움 척도
- process macro
- invariance test
- mediation
- EFA