
티스토리 뷰
바로 이 전 포스팅에서 데이터를 시각적으로, 그리고 요약된 정보를 보는 방법을 배웠어요.
데이터 기술 통계량 보기
이어서 이번에는 먼저 요약된 정보들을 정리를 해볼까요?
표로 집어넣어 볼게요.
dplyr 라는 패키지를 사용할거예요.
먼저 설치를 해야죠?
install.packages("dplyr", denpendencies = T)
dependencies는 만약 dplyr을 실행하기 위해 필요한 다른 패키지가 있으면 같이 설치하는 거예요.
T는 TRUE예요. TRUE라고 넣어도 돼요.
그리고 semTools라는 패키지도 설치할게요.
install.packages("semTools", dependencies = T)
딸린 애들이 많으니 인내심을 갖고 기다리세요.
semTools는 SEM을 위한 툴이긴한데 여러 쓸모가 많아요.
설치가 끝나면 실행시켜줘요.
library(dplyr)
library(semTools)
library가 뒤의 패키지를 activate 하는 기능어예요.

여기까지 따라오셨죠?
(제 데이터 프레임 이름이 RLSPSS인거 기억하시죠? 혹시 가물가물하시면 이 전 포스팅으로 가보세요.)
이번에는 chaining 혹은 piping 이라는걸 쓸거예요.
dplyr에 속한 기능이예요. 예를 들어볼게요.
View(RLSPSS %>% group_by(Age) %>% summarize(group_n=n()))
이게 뭐냐고요?ㅋㅋ
자, View는 이제 익숙해졌을테고,
%>%이게 chain 혹은 pipe operator 이예요.
컨트롤(Ctrl)+쉬프트(Shift)+M 누르면 쉽게 나와요.
이 뜻은 가장 왼쪽부터 시작해서, RLSPSS데이터를 이용해서 group_by(Age)를 하고,
group_by(Age)를 이용해서 summarize(group_n=n())을 해라 라는 의미예요.
그럼 group_by(Age)는 어쩌라는 걸까요?
group_by()는 ()안에 들어가는 변수를 그룹으로 잡는거예요.
summarize로 다양한 수치들을 요약할 수 있고요,
뒤에 따라오는 group_n은 제가 임의로 붙여준 이름이고, n()이건 빈도예요.
다시 그럼 큰 그림으로 돌아가서,
View(RLSPSS %>% group_by(Age) %>% summarize(group_n=n()))
RLSPSS데이터 프레임에서, Age를 기준으로 그룹을 잡고, 각 그룹의 빈도를 보여줘.
라는 의미인거예요.

결과는 다음과 같아요.

이해가 돼죠?
이제 descriptive statistics를 좀 더 추가해볼게요.
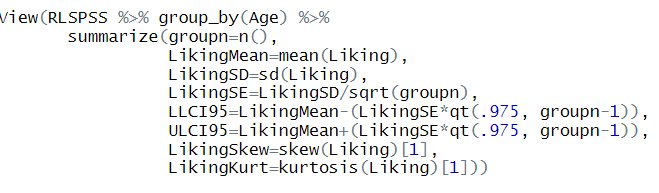
=의 왼쪽 부분은 제가 이름을 붙힌거고요(위의 groupn처럼요)
Age 그룹에 따른 Liking점수를 볼거예요.
평균과 표준편차는 각각 mean 과 sd 를 이용해서 계산하면 돼요.
그리고 신뢰구간을 계산하기 위해 표준오차를 먼저 계산했어요.
표준오차(SE) = 표준편차(SD)/루트n 인거 기억하시나요?
그래서 LikingSD/sqrt(groupn)
이 수식이 나왔어요. sqrt는 squared root고요.
그리고 그 아래 LLCI는 lower level confidence interval 이라는 뜻으로 넣었고요
95는 95%신뢰구간이라는 뜻으로 넣었어요.
ULCI는 upper level confidence interval 이란 의미고요.
제가 정한 이름이니 편한대로 설정하시고,
신뢰구간 계산하는거 기억나시나요?
평균 - t(n-1)*표준오차가 95% LLCI
평균 + t(n-1)*표준오차가 95% ULCI
대충 이런식이죠?
LLCI95=LikingMean-(LikingSE*qt(.975, groupn-1))
LikingMean은 평균, LikingSE는 표준오차, qt는 quartile로 95% 신뢰구간이라면 .975, 90%신뢰구간이라면 .95 하시면 돼고, groupn-1는 자유도
저렇게 계산했어요.
신뢰구간 계산 방법을 이해하고 있다면 어렵지 않을거예요.
그리고 그 아래 skewness와 kurtosis때문에 semTools를 넣었는데요.
뒤에 [1]이 붙는 이유는,
skew(RLSPSS$Liking)
이렇게 그냥 보면 4개의 결과물이 나와요. skew, se, z, p 이렇게요.
물론 여기서 se는 skew의 표준오차고 다 skewness에 관한거예요.
이 중에 [1]라고 함으로써 skew 수치만 보여줘 라고 한거예요.

전체적으로 이런 결과를 볼 수 있을거예요.
Data converting
이번엔 converting을 해볼까요?
만약 연속형 데이터를 그룹으로 바꾸고 싶다고 해봐요.
저는 Liking 점수를 그룹화해볼게요.
먼저 데이터 프레임안에 변수 이름을 만들어줄거예요.


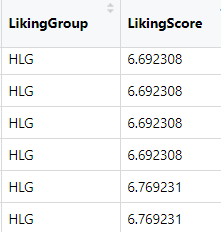
결측치로 채워진 새 LikingGroup변수를 만들었고, LikingScore를 보기 좋게 옆으로 옮겨놨어요.
(사실 이렇게 하지 않고 저 두 세로줄만 선택해서 볼 수도 있어요.
View(select(RLSPSS, c(LikingGroup, Liking)))
이렇게요.)
그리고 평균과 표준편차 값을 이용하기 위해
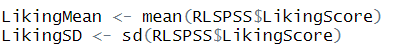
이렇게 만들어놨어요.
먼저 Liking점수가 낮은 그룹을 지정해볼게요.

평균-1SD 보다 낮은 값을 LLG, 즉 low liking group으로 지정했어요.

이번엔 높은 그룹이예요.
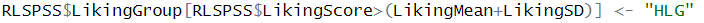
LikingMean+LikingSD, 즉 평균+1SD보다 큰 값을 높은 그룹으로 지정했어요.
그 사이 중간 그룹은 어떻게 할까요?

이렇게 &를 이용하면 돼요.
그리고 SPSS에서의 filter기능처럼 어떤 데이터만 선택하고 싶으면 어떻게 할까요?
dplyr 패키지를 이용해서, 나이가 20세 이하인 샘플만 골라볼까요?
under20 <- filter(RLSPSS, Age<=20)

만약 이 under20 데이터를 따로 저장하고 싶다? 그럼
write.csv(under20, file="under20.csv", row.names = F)
이런식으로 저장하면 돼요.
만약 row.names = T로 하면

요 가장 왼쪽에 1, 2, 3, 4, 있죠? ID 옆에요.
저게 가장 첫째 세로줄로 와요.
할 수 있는게 너무 많아서 다 다루기 힘들지만 사실 아직까지는 R과 익숙해지기 위한 단계라고 생각해요.
다음 포스팅에서는 본격적으로 개별 패키지들을 다뤄볼께요.
재밌는 연구하세요!
도움이 됐다면 커피 한 잔 사주시면 감사하겠습니다^^
EPIK is 어려운 지식을 가능한 한 쉽게 공유하는 곳이예요 :)
Hey 👋 I just created a page here. You can now buy me a coffee!
www.buymeacoffee.com
'통계 이야기 > R을 공부해보자' 카테고리의 다른 글
| R 데이터를 살펴보자 (0) | 2020.06.08 |
|---|---|
| R 데이터 불러오기 (0) | 2020.06.07 |
| R 기초 2 (갖고 놀기) (0) | 2020.06.05 |
| R 기초 1 (갖고 놀기) (0) | 2020.06.03 |
| R 입문! (설치 및 세팅) (0) | 2020.06.03 |
- moderation
- close relationships
- MLM
- EFA
- multilevel
- Mplus
- 구조방정식
- 탐색적 요인분석
- 매개효과
- 간접효과
- structural equation modeling
- indirect effect
- social exclusion
- process
- 조절분석
- invariance test
- 소속감
- 논문통계
- SEM
- 사회심리
- rstudio
- Hayes
- probing
- R 기초
- exploratory factor analysis
- process macro
- amos
- mediation
- 부정적 평가 두려움 척도
- 프로세스