
 프로세스(PROCESS) 모델 1번
프로세스(PROCESS) 모델 1번
자 오늘부터 프로세스 모델 넘버순으로 차근차근 살펴보려고 해요.버전별로 모델 넘버가 달라질 수 있으니 참고하시고, 제가 사용하는 버전은 4.2입니다. 오늘 다룰 모델 1번은 아래 그림과 같아요.하나의 조절변수가 X → Y에 영향을 미치는지 볼 때 사용하는 모델이네요. 우리가 조절변수의 영향을 볼 때 어떻게 계산하죠? Interaction term, 즉 상호작용항을 만들어서 회귀식에 넣죠?즉, X가 독립변수, Y가 종속변수, M이 조절변수일 때,Y = a + b1X + b2M + b3XM위의 회귀식을 통해서 우리는 조절변수의 영향이 있는지 알아볼 수 있어요. PROCESS도 이와 같은 회귀식을 이용해서 분석을 해요. SPSS 데이터 파일 열어놓으셨죠?PROCESS 설치는 하셨나요? 안하셨다면 아래 포스팅 ..
 PROCESS 설치 [업데이트]
PROCESS 설치 [업데이트]
[통계 이야기/PROCESS] - PROCESS 설치 [구버전] PROCESS 설치PROCESS는 쉽게 말하면 복잡한 매개 분석이나 조절 분석 등을 쉽게 해주는 툴이라고 생각하면 돼요. 상당히 유용하면서, 신뢰도 높고, 다소 정확하며, 쉬워요. 거기다 공짜! 계속해서 업데이트 되study-easy.tistory.com[통계 이야기/PROCESS] - PROCESS 기본 (GUI) PROCESS 기본 (GUI)이제부터 차근차근 PROCESS에서 다룰 수 있는 분석들을 살펴볼거예요. 그 전에 PROCESS 를 이용해 분석을 할 때 설정을 어떻게 해주고, 각각이 뭘 의미하는지 알아볼게요. [통계 이야기/PROCESS] - PROCESSstudy-easy.tistory.com 예전에 PROCESS 설치 방법 등..
 중심화 경향이 뭘까?
중심화 경향이 뭘까?
통계 기초에 관해 공부하다 보면 central tendency (중심화 경향)라는 말이 나와요. 이게 뭘까요? 예를 들어서, 시험에서 80점을 맞았다고 해봐요. 잘 본걸까요 못 본걸까요? 그 시험을 본 사람들이 대체로 몇 점을 맞았는가에 따라서 기본적인 비교가 가능하겠죠? 중심화 경향은 어떠한 데이터를 대표하는 값을 구하는 거예요. 대표적으로는 산술평균, 중앙값, 최빈값이 있어요. Mean (평균, 주로 산술평균 arithmetic mean) 가장 친근한게 이 평균값이죠? 평균값은 모든 수치를 더한 후 자료의 개수로 나눠줘요. 데이터가 {1, 2, 3} 이라면 평균값은 (1+2+3)/3 이게 평균값이예요. 이 평균값은 균형점이라고 생각하면 좋아요. 이렇게 균형을 잡고 있는데 데이터 하나가 추가되면서 16..
제 머리속에는 척도가 마치 고등학교 수학의 행렬 같은 존재라고 인식되어 있어요. 언제나 헷갈려서 항상 여기로 돌아오고, 기초를 공부할 때 척도가 챕터1 같은 느낌이예요. 이제 다시는 돌아오지 말아요! Nominal (명목) 우리한테 포도 한 송이와 사과 한 개, 그리고 바나나 한 개가 있다고 해봐요. 이 과일을 수치와 하려고 포도=1, 사과=2, 바나나=3 이렇게 바꿨어요. 각각의 숫자들은 이제 단 하나의 의미만 가지고 있어요. 1은 포도 2는 사과 3은 바나나. 2가 1보다 큰가요? 1+2=3 인가요? 아니죠? 사과(2)가 포도(1)보다 클 수도 있고 작을수도 있고, 포도(1)+사과(2)=바나나(3)는 절대 아니죠? 명목척도에서는 숫자들에 크기나 순서 이런 것들이 전혀 없어요. 따라서 이 숫자들을 더하..
이번 가을 학기 강의하면서 통계의 기초에 대한 공부를 다시 해봤어요. 이미 기초를 넘어선 분들이 많겠지만, 언제나 새롭게 시작하시는 분들이 있으니 이번에는 기초적인 부분을 끄적여볼게요. Descriptive Statistics (기술 통계)? 기술통계(띄는게 맞는걸까요? 흠..)는 영어를 보면 쉬워요. Descriptive, 즉 어떤 데이터를 describe, 묘사하는 거예요. 현재 내가 갖고 있는 데이터를 요약하는 거라고 생각하면 돼요. 예를 들어, 100명의 응답을 모은 후 얼마나 많은 사람들이 현재 정권을 지지하는지 본다면 이건 기술 통계예요. Inferential Statistics (추리 통계)? 추리통계는 추론을 하는거예요. 한국인 전체가 현재 정권을 얼마나 지지하는지 보려면 엄청난 돈과 시간..
 R 데이터를 살펴보자 2
R 데이터를 살펴보자 2
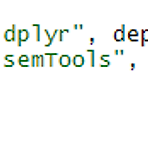
바로 이 전 포스팅에서 데이터를 시각적으로, 그리고 요약된 정보를 보는 방법을 배웠어요. 데이터 기술 통계량 보기 이어서 이번에는 먼저 요약된 정보들을 정리를 해볼까요? 표로 집어넣어 볼게요. dplyr 라는 패키지를 사용할거예요. 먼저 설치를 해야죠? install.packages("dplyr", denpendencies = T) dependencies는 만약 dplyr을 실행하기 위해 필요한 다른 패키지가 있으면 같이 설치하는 거예요. T는 TRUE예요. TRUE라고 넣어도 돼요. 그리고 semTools라는 패키지도 설치할게요. install.packages("semTools", dependencies = T) 딸린 애들이 많으니 인내심을 갖고 기다리세요. semTools는 SEM을 위한 툴이긴한..
 R 데이터를 살펴보자
R 데이터를 살펴보자
바로 전 포스팅에서 데이터를 불러오고, 간단하게 데이터를 어떻게 보는지 알아봤어요. 오늘은 다양한 방법으로 데이터를 살펴볼거예요. 먼저 시각적으로 살펴볼까요? 저번 포스팅에서 저는 RLSPSS라는 데이터 프레임을 만들었어요. 쉽게 말하면 RLSPSS라는 이름 아래 제 데이터를 넣었어요. 이를 이용해서 간단하게 각 나이별로 분포가 어떻게 되는지 대략적으로 봐볼게요. 다양한 그래프로 데이터 살펴보기 먼저 그냥 수치를 봐도 돼요. table(RLSPSS$Age) 제 데이터에서 나이 변수 이름이 Age예요. 저렇게 RLSPSS 데이터 프레임 안에서 Age의 테이블을 보겠다 라고 치면 이렇게 나오죠. 그럼 이걸 그래프로 보고싶다면? barplot(table(RLSPSS$Age)) 이렇게 하면 이런 그래프가..
 R 데이터 불러오기
R 데이터 불러오기
오늘은 R을 이용해서 기존에 갖고 있던 데이터를 불러와볼거예요. Working Directory 먼저 파일을 저장할 폴더를 지정해볼까요? 원래 있던 폴더를 연결해서 파일들을 저장하시려면 setwd 기능을 이용하시면 돼요. setwd("C:/Users/.../Desktop/R Practice") 이게 웃긴게 그냥 폴더 주소를 복사해서 붙여넣으면 C:\Users\...\Desktop\R Practice 이렇게 나와요. 그대로 복사 붙여넣기 하면 안돼요. 저 \표시를 /로 바꿔줘야 해요. 파일 불러오기 이제 working 폴더를 지정해줬어요. 이번에는 csv 확장자로 된 데이터를 불러올게요. read.csv라는 명령어를 이용해서, NewData ... 원하는거 불러오면 돼요. Haven 이라는 패키지를..
- 매개효과
- moderation
- close relationships
- Hayes
- R 기초
- rstudio
- EFA
- MLM
- 탐색적 요인분석
- 소속감
- 논문통계
- 부정적 평가 두려움 척도
- mediation
- invariance test
- process macro
- structural equation modeling
- probing
- indirect effect
- exploratory factor analysis
- process
- Mplus
- 간접효과
- 구조방정식
- social exclusion
- amos
- 사회심리
- SEM
- multilevel
- 프로세스
- 조절분석